ZooScan - Part 5: Multi-Label vs. Multi-Class Classification
In the previous post, we completed a first version of our app, which can spice up your visits to a zoo by identifying the animals you see. If, like me, you took it for a spin to your local zoo, you might have noticed that the app is not perfect. It can sometimes misidentify animals, and it can also fail to assign a label at the correct level of specificity. For example, it might identify a zebra as a horse, or it might not recognize a Labrador as a “canine” or even a “mammal”. Why does this happen? We will explore the answer to this question in this post.
Before we continue, I would like to remind you that this post is part of a series of posts about the ZooScan app, an overview of which can be found in the courses section.
Evaluating the First Version of ZooScan - Challenges and Limitations #
After finishing the first version of the app, I started testing the model with various images of animals I took during our numerous visits to zoos. I quickly noticed that while sometimes the model correctly identified the animal, mostly it would assign a label that was too general or would not be related to the animal at all. To show you what I mean, let’s take a look at some examples of the model’s predictions.
The first photograph that I tested was the following picture of a rhinoceros. As you can see, the picture clearly contains several rhinoceroses, but the model classified the image as the more generic “animal”.

The detail screen of ZooScan showing a wrong classification of a rhinoceros
To see what’s happening here, first let’s add some logging to the app to see what predictions the model makes.
In your VisionClassificationModel.swift file, add the following code to the classifyImage at the end of the function, right before the return statement:
{
...
for classification in results {
print("Classification: \(classification.identifier), Confidence: \(classification.confidence)")
}
print("\n\n")
return ClassificationResult(label: bestResult.identifier, confidence: Double(bestResult.confidence))
}
As we have seen in the previous post, the model returns a list of classifications with their confidence scores. The logging code above will print these classification labels
(i.e. the classification.identifier) and their confidence scores to the console. If we look at the first five
lines in the console output, for the rhinoceros image, we see the following:
Classification: animal, Confidence: 0.9345703
Classification: mammal, Confidence: 0.9345703
Classification: rhinoceros, Confidence: 0.9345703
Classification: structure, Confidence: 0.7968631
Classification: fence, Confidence: 0.7963867
We see that the model predicts multiple labels for the image. We also see that there are multiple labels with the same confidence score. The top three labels (“animal”, “mammal”, and “rhinoceros”) all have a confidence score of 0.9345703, which is a very high confidence. Because all the labels have the same confidence score, the model picks the first one, which is “animal”. In this case, that label is too generic.
Let’s look at another example, this time with a giraffe. The model again does not identify the animal as a giraffe, but it also assigns a label “outdoor”.
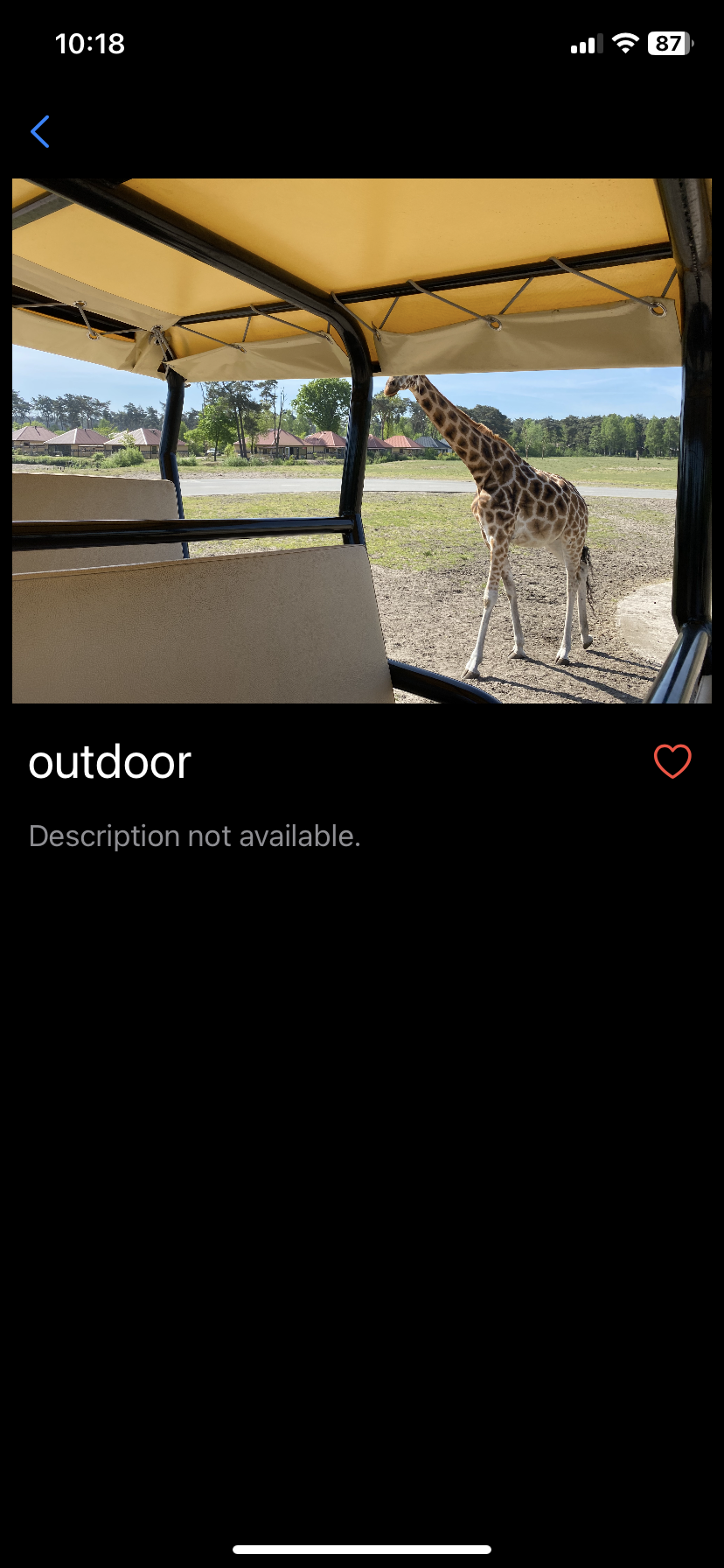
The detail screen of ZooScan showing a wrong classification for a photo of a giraffe
If we look at the console output for this image, we see the following predictions:
Classification: outdoor, Confidence: 0.8255457
Classification: land, Confidence: 0.7929754
Classification: grass, Confidence: 0.79296875
Classification: animal, Confidence: 0.7685547
Classification: giraffe, Confidence: 0.7685547
We can see that the problem here is a bit different. The correct label “giraffe” is present in the list of predictions, but it is not the one with the highest confidence score. Giraffe has the second-highest confidence score, but comes fifth in the list of predictions. The model picks the first label, which is “outdoor”, and may be a good label to describe the image. Actually all labels describe our images correctly, but this is not what we want to see in our app. We would like to see the app label the animals in the image, and provide the most specific label possible.
The main issue here is that the model used by the Vision framework is aimed at providing multiple labels for an image. Think here about the use case of Apple Photos, which uses such a model to assign multiple labels to a photograph. Using such a model makes the photograph searchable, and allows the user to find the photograph by searching for any of the labels. In our case, we are not interested in multiple labels, but rather in a single label that is as specific as possible. Moreover, we are only interested in animal-related labels - not general ones labels like “outdoor” or “structure”. Summarizing, we have two problems:
- The model assigns multiple labels with a high confidence to an image, and we are only interested in the most specific label.
- The model assigns labels that are not related to animals, and we want to filter those out.
In this post, we will explore the first problem. In the next post, we will take a look at the second problem.
Multi-Label vs. Multi-Class Classification #
We have seen that the model used by the Vision framework is designed to provide multiple
labels for an image. This is known as multi-label classification, where each image can be
assigned multiple labels, several images can have the same high confidence score. The labels
are not mutually exclusive, meaning that an image can belong to multiple categories at the same
time. For example, an image of a zebra can be labeled as both “zebra”, “mammal”, and “animal”.
Each of these labels are also correct labels for a zebra.
However, in our use-case we are not interested in multiple labels, but rather in a single label that is as specific as possible. We would like mutually exclusive labels, where each image is assigned a single label from a set of classes. This is known as multi-class classification. In multi-class classification, each image can only belong to one class at a time. That class gets the highest confidence score.
The model used by the Vision framework has, at the time of writing this post, 1303 classes.
Being a multi-label classification model, it can pick more than one class out of these 1303 classes. While there are more ways to create a multi-label classification model, it can help to think of it as a set of independent binary classifiers. The model makes a binary decision for each class, whether the class is present in the image or not. Each of these predictions have a confidence score, which indicates how confident the model is that the class is present in the image. The model then returns a list of classes with their confidence scores, sorted by confidence score.
Conversely, had the model been a multi-class classification model, it would have returned a
single class with the highest confidence score from the 1303 classes. In our case, we would
like to use a multi-class classification model, which returns a single label that is as
specific as possible. This will solve both of the problems we have seen above. However, this
will require us to train a new model, which is not straightforward. In the next post, therefore
we will focus on using the Vision model in such a way that it will select the most specific
animal-related label from the model. The approach we present will also filter out the predictions that are not related to animals. In this way, we will, since we are already talking about animals, kill two birds with one stone 😉.
Conclusion #
In this post, we evaluated the first version of our ZooScan app. We saw that the predictions it
made were not always the predictions that we wanted to see. Sometimes, the predictions were too generic, and sometimes they were not related to animals at all. A more detailed analysis of the model’s predictions showed that the correct prediction was often present in the top-5 best predictions. We identified the problem as being related to the fact that the model used by the Vision framework is a multi-label classification model. We contrasted this with a multi-class classification model, that would be more suitable for our use case. For now, we will try to adapt the Vision multi-label model for our purposes. In the next post therefore, we will explore how to use the multi-label classification model in such a way that it will return the most specific animal-related label for an image.
